

Markdown 是个好东西。
— Weibin Luo
需要解决的问题
最近在写 Markdown 的时候需要需要写一些外部的链接, 按我的个人习惯一般采用这样的格式来写:
1
[{Page Title}]({Url})
举个例子:
介绍几个自动生成 Markdown 链接的软件 | Amabel
这么写虽然比较美观,但是每次都需要自己去 HTML 的代码中找 <title> 标签并取得网页的标题,非常花时间。
于是我希望有一款工具,当我输入网页地址时可以自动取得并返回网页的标题, 或是直接帮我自动生成 Markdown 格式的链接,等待我去拷贝。 更甚至是直接自动帮我拷贝到剪切板,那可就太完美了。
这个功能实现起来并不困难,我在 3 年前曾做过同样的功能,可惜疏于维护。这个我们最后再说。
解决思路
功能比较简单,那么就说一下思路吧。
我们的目标是要取得 HTML 中 <head> 下面 <title> 元素的内容, 那么我们只要发起一个 GET 请求来取得网页的内容,之后解析网页的内容并取得相应元素的内容即可。
获得 title 之后,我们再把 title 和 url 组合成 Markdown 格式的链接就算基本完成啦。
然后有条件的话,还可以加一些自动拷贝,或是让用户自己指定输出格式的功能。
以上只能算是实现了最基本的功能。我们还需要考虑一些边界的情况。 比如当返回的内容中含有 Markdown 的特殊的字符的时候,我们需要将其转义(Escape), 以此来防止 XSS 攻击以及 Markdown 的格式被破坏。
典型的需要转义的 Markdown 的特殊字符有:
\ ` * _ { } [ ] ( ) # + - . !此外,为了防止 XSS 攻击,我们还需要将
<script>标签中的字符进行转义。所以还要加上<和>这 2 个字符。
几个现成的小工具
虽说功能简单,但是把以前的项目捡起来重新维护也需要额外的时间和精力。
于是尝试性地谷歌了一波之后,我找到了几个比较有意思且符合我需求的小工具。在这里分享并简单介绍一下实现的原理。
这里主要还是介绍一下本体功能的实现原理,平台(Chrome,VSCode 扩展)相关的一些东西就不写啦。
Copy Title & Url as Markdown Style
仓库地址:GitHub - zaki-yama/copy-title-and-url-as-markdown
这是一款 Chrome 扩展。看名字就知道它是干什么的了! 安装扩展之后,打开你要生成链接的网页并点击扩展, 大约 0.3 秒之后 Markdown 格式的链接就自动到拷贝你的剪切板了。
从结果来说非常符合我的需求,美中不足的是必须自己先访问想要生成链接的网页。
代码分析
来看看具体是怎么实现的。
我们主要关注以下几个文件:
在 background.ts 中,我截取了一部分关键的代码,并添加了一些注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import { INITIAL_OPTION_VALUES } from "./constant";
import { escapeBrackets, copyToClipboard } from "./util";
chrome.tabs.query(queryInfo, function (tabs) {
chrome.storage.local.get(INITIAL_OPTION_VALUES, function (options) {
const tab = tabs[0];
// 从 Chrome 的当前 tab 中直接获取页面的 title 和 url
const title = tab.title || "";
const url = tab.url || "";
const tabId = tab.id || 0;
chrome.scripting.executeScript({
target: { tabId },
func: copyToClipboard, // 执行 copyToClipboard 方法
args: [options[key], title, escapeBrackets(url)], // 将 title 以及转以后的 url 作为方法的参数
});
});
这个实现思路可以说是十分巧妙,通过从 Chrome 的 tab 中直接获取页面的 title 和 url, 就不需要特地再去发一次 GET 请求来获得相关的信息了。
另外我们还看到对 url 使用了 escapeBrackets 方法,这个方法是从 src/util.ts 中引入的。
1
2
3
4
5
6
7
export function escapeBrackets(str: string) {
return str
.replace(/\(/g, escape)
.replace(/\)/g, escape)
.replace(/\[/g, escape)
.replace(/\]/g, escape); // 对一些括号字符进行了转义
}
在 escapeBrackets 方法中,对一部分括号的字符进行了转义。 这样可以保证页面的 title 中出现这类字符的时候也可以正常显示 Markdown 格式的链接。
但由于没有对所有特殊字符进行转义,所以当 title 中出现其他特殊字符的时候可能会导致页面显示不正常。 此外,由于没有转义 < 和 > 这 2 个字符,所以有可能会遭到 XSS 攻击。(这个地方可以考虑改进,提个 PR 什么的)
最后再来看看 src/constant.ts:
1
2
3
4
5
6
7
8
// markdown style
export const DEFAULT_FORMAT = "[${title}](${url})";
export const INITIAL_OPTION_VALUES: OptionsType = {
format: DEFAULT_FORMAT,
optionalFormat1: "",
optionalFormat2: "",
};
这里主要的功能是用户可以自己定义最终输出的格式, 在最终调用 copyToClipboard 时会先转换为定义好的格式 在某些情况下应该比较有用。
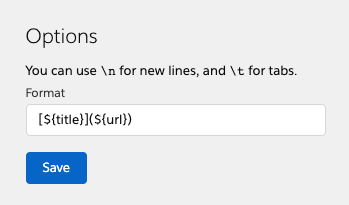 可以在设置页面自定义输出的格式
可以在设置页面自定义输出的格式
markdown-link-expander
仓库地址:GitHub - Skn0tt/markdown-link-expander
再来看另一个。
这是一个 VSCode 扩展。主要的功能是在 VSCode 中选中 url 后运行扩展, 会自动把 url 替换为 Markdown 格式的链接。 配合自定义的快捷键使用,可以说是直接起飞。
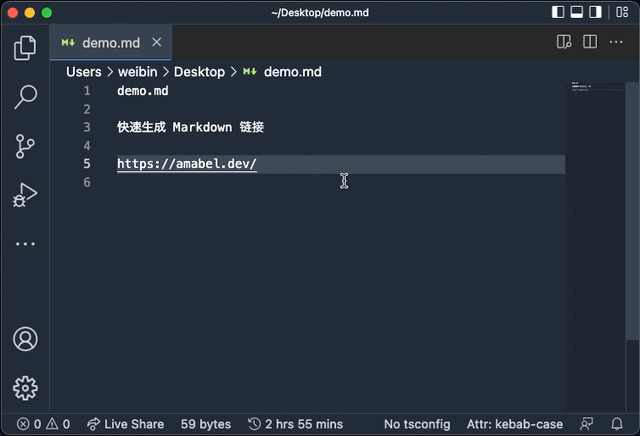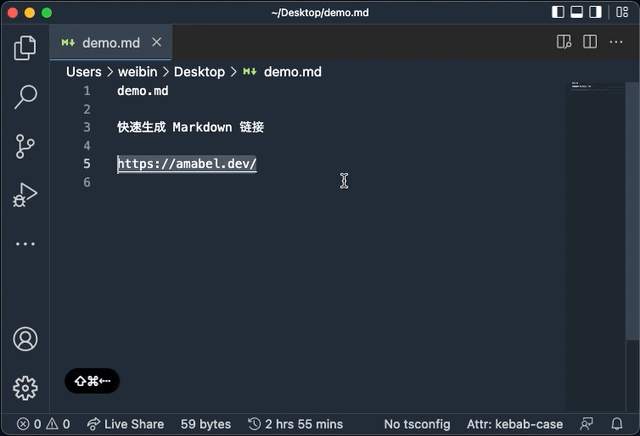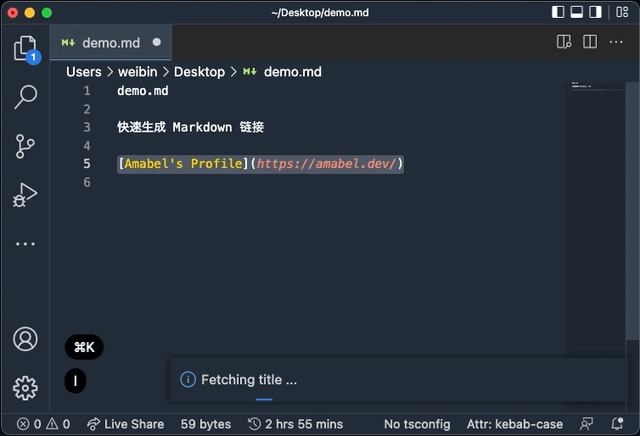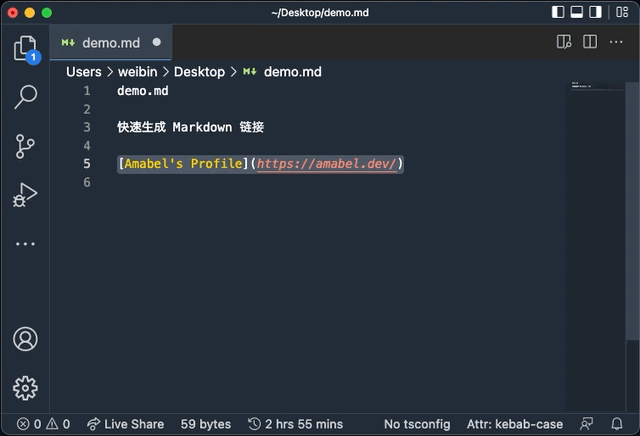 效率起飞
效率起飞
代码分析
我们主要关注 2 个文件:
在 src/extension.ts 中,先是进行了一些 VSCode 扩展的相关的注册, 剩下的主要的部分我已经写了一些注释。
首先通过 fetchTitle 方法获得页面的 title,然后转换为 Markdown 格式的链接并直接替换选中的文本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import * as vscode from "vscode";
import { fetchTitle } from "./fetchTitle";
export function activate(context: vscode.ExtensionContext) {
const disposable = vscode.commands.registerCommand(
"markdown-link-expander.expand",
async () => {
// ...
const document = editor.document;
const selection = editor.selection;
let url = document.getText(selection);
// ...
await vscode.window.withProgress(
{ location: vscode.ProgressLocation.Notification, title: "Fetching title ..." },
async () => {
try {
const title = await fetchTitle(url); // 获取 title
const markdownLink = `[${title}](${url})`; // 生成 Markdown 格式的链接
editor.edit((editBuilder) => {
editBuilder.replace(selection, markdownLink); // 替换文本
});
} catch (error) {
vscode.window.showErrorMessage("Failed to fetch title.");
}
}
);
}
);
}
再来看 src/fetchTitle.ts:
1
2
3
4
5
6
7
8
9
import axios from "axios";
import * as cheerio from "cheerio";
export async function fetchTitle(url: string): Promise<string> {
const res = await axios.get<string>(url);
const $ = cheerio.load(res.data);
const title = $("title").text().trim();
return title;
}
和上面讲过的思路相似,fetchTitle 方法通过 axios 发起一个 GET 请求, 然后使用 cherrio 解析网页,并获取 title 的内容。
需要注意的是,这个工具和上面的 Chrome 扩展一样,没有把特殊字符进行转义, 所以仍然会存在格式问题和安全隐患。
虽然在特殊字符的处理上不是很完美,需要手动调整, 但是这个扩展对我来说已经非常够用了。
作为一名开源爱好者,这个时候应该提一个改进的 PR, 但是由于这个仓库好像已经 1 年多没有维护了,所以也没有提 PR 的打算。 说不定将来可以 Fork 下来或者自己写一个 VSCode 扩展。
3 年前的项目
GitHub - Amabel/md-link 是我在 3 年前写的一个小工具。
实现的思路还是通过 axios 发送 GET 请求来获取页面的 title。 调用它后会返回以下 JSON:
1
{"title":"Amabel's Profile","url":"https://amabel.dev"}
当时主要是想着用 axios 来实现,但是考虑到用户端可能没有 Node.js 或是浏览器环境, 所以灵机一动直接用 AWS Lambda 和 API Gateway 来做一个 API, 这样用户只要通过 cURL 调用 API 就可以很快拿到结果了。
现在仔细一想,既然都可以用 cURL 了,那为什么不直接向网站发 GET 请求然后处理得到的结果呢? (我觉得这个想法非常不错,可以考虑做成一个 brew 的 formula)
提几个可以改进的地方,留着以后参考:
- 用 Serverless 框架来改善部署的设定和步骤
- 提供网页版和 npm 包等多种版本,方便使用
- 增加对特殊字符的转义
- 提供多种输出格式,方便拷贝
- README 要认真写!